故障最初表现是这样的,在客户端正常连接一段时间之后,无任何征兆的服务端会突然触发close事件从而进行连接断开的清理工作,将Redis和Mysql内的在线数据都清理掉了,导致推送时找不到该设备,但是客户端直接请求服务端的数据,服务端均能够正确响应。
最初以为是node的ws模块有bug,在触发close事件的时候并没有真正关闭连接,所以在close事件触发的时候直接调用了socket._socket.close()来强制关闭连接,然而并没有什么卵用,情况并没有任何变化。
随后开始了wireshark抓包,发现故障时,客户端会发来未知的opcode
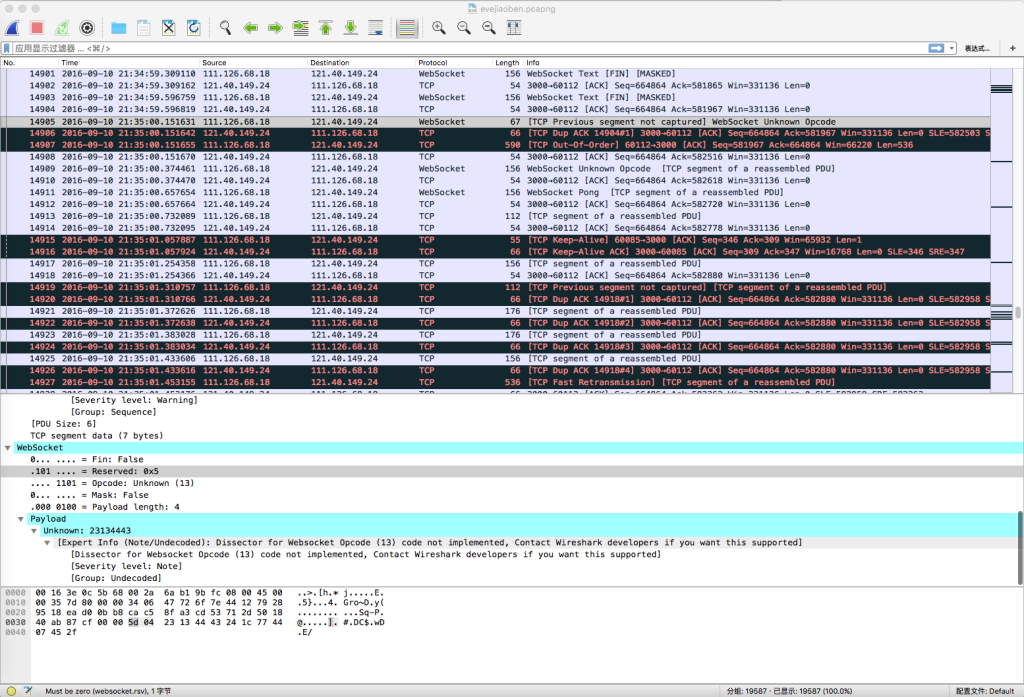
在服务端收到这个错误的opcode后,理应关闭的连接并没有被关闭,服务器从这个包之后只回复tcp的ack,并且所有数据包只被识别为tcp,识别不出websocket的协议层。所以将检查的重点放在了这个数据包上。仔细阅读ws源码后,却并没有发现什么,一时陷入了僵局。
后来客户端进行了单独抓包,但是尽管也抓到了unknown opcode的数据包,但是,服务端能够正常处理,出现故障的时候,并没有异常数据包。
实在没办法了,只好在服务器上开断点调试,后来突然发现,如果是服务端重启后客户端连接或者客户端重启进行连接,都是不会触发故障的,只有唯一一种情况,客户端掉网后重连,过一段时间就会出现故障。
仔细想了想,客户端掉网重连的唯一特点是TCP会一直等到超时,才会触发断开连接。而程序层的keepAlive只做了客户端到服务端的,个别情况下客户端会卡住,所以服务端并没有做keepAlive的超时判断,这就导致了一旦客户端由于网络原因掉连接,服务端没有收到FIN数据包,客户端keepAlive超时判断断开连接,服务端也收不到RST包。
此时,客户端重新连接,并且完成登录过程后,若旧连接的TCP层keepAlive到期,服务端会触发close事件,缓存对应的是用户和设备ID,从而新旧连接共用的一套缓存key,导致旧连接清空对应的Redis和Mysql缓存,表现上就是新连接触发了close事件清空缓存。
知道了问题所在后自然也就有解决方法了,由于node运行在cluster模式下,所以在redis中记录设备id对应的自增connectionId,为了防止跨cluster造成的数据重叠,connectionId生成用的是${process.pid}!${connectionId++},每次断开连接时判断redis中的设备id对应的connectionId,如果不是就说明当前设备后来有登陆过,当前连接不做清理操作。